
Reducing Friction in Software Deployment/Release Process
I truly believe that for a software engineering team to innovate, it must find a way to reduce development-to-deployment friction as much as possible. Imagine being in an architecture/design meeting, and a team member suggests a wild, unconventional way of solving a problem that is so crazy, it might just actually work??!?
Would the team consider spiking on this wildly different approach if it took weeks and involvement of other teams to build the infrastructure? Probably not. What if it took several days? Maybe. What if an engineer in the team could launch a sandboxed deployment environment in minutes and possibly have a working prototype in hours? Would the team invest the time to test out this new idea then??? I think most teams would say F#CK YEAH!
Every software development organization should make it one of their main missions to reduce developer deployment friction. The less of a burden it is to launch new services and applications:
- the more engineers will try out new things
- the more open minded they are to tear down, redesign and rebuild applications
- the more likely they are to discover and find the right solutions
This wildly agile approach to deployment, as chaotic as it seems, can ultimately lead to innovation.
Infrastructure-As-Code
Wouldn't it be great if you could create an Amazon Web Services account, check out a project on GitHub, update some parameters, run terraform apply and then voila! - FRESH OUT THE OVEN - you've got a brand new deployment environment that closely mimics the rest of the environments in your infrastructure? I mean, VPCs, Private and Public Subnets, NAT Gateways, Databases, IAM Policies, etc. Now, that is sexy.
By the way, if you are not using Terraform to build your infrastructure, you should check it out. It's the next best thing since sliced bread. But this blog post isn't about Terraform. You should visit my buddy Adam Gibbon's tutorial. It's got some really good information on how to get started.
Building Microservices with the Serverless Framework and Standardized Gradle Projects
We use Terraform to build common infrastructure resources - Network setup, S3 buckets, Elastic Search, etc. But when it's time actually build and deploy APIs and applications in our Service-Oriented architecture, we rely on the Serverless Framework to manage and create microservices-related resources - I'm talking about API Gateway Endpoints, Dead Letter SQS queues, etc. Any AWS resource that needs to be deleted when the service is removed, is managed by the Serverless Framework. Whether you need to expose an HTTP REST endpoint, invoke a function on a scheduled interval, or react to an SNS event, the framework handles all of the configuration and creation of resources. You just focus on the function's business logic. It's an amazing toolkit! It's the "Easy Button" of Serverless development. And if you are using NodeJS to develop your functions, you may not even need a separate packaging tool.
You might be asking, where does Gradle fit in to all of this? Well, first I love the JVM and we develop our Lambda functions on the JVM. Oh you don't??? It's okay, nobody is perfect =) The Java Virtual Machine is an amazing piece of engineering. It made Scala, Clojure, Groovy, Kotlin, etc. possible. Java powers tens (if not hundreds) of billions of servers and devices. Yes you heard that right, billions. It has been the bedrock of the majority of financial and e-commerce systems for quite some time. And when it's time for startups to grow up and scale, many move to the JVM platform. But that's all I'm going to say about the JVM for now.
Now back to Gradle. I think it's the best build tool out there. I've worked with many build tools including Make, Ant, Maven, Grunt, Gulp, etc. to name a few. Gradle is my absolute favorite. It's enjoyable to use and most of all, it's very easy to extend and customize. Oh, you need to generate a build.json file at the end of the build that contains the location and version of the binary artifact? No problem. Here's a simple task to add to the build.gradle. No plugins needed, no hassle, just write the task and call it a day.
Short and sweet, right??? I haven't had a reason to write bash scripts related to builds in a long time. I always default to Gradle. It gets the job done.
Moving on...
So far we've talked about using Terraform to build common infrastructure-wide resources and using the Serverless Framework to manage microservice-scoped resources.
Now that we're deploying microservices left and right because the process is so painless, what else can we do to further make our lives easier as engineers???
Let's face it. Developing applications isn't just about writing code and pushing it to production. We need think about tests, code coverage, continuous integration, logging, monitoring, error reporting, bug tracking, retry strategy, etc. The key is to standardize your projects and enforce good software development conventions so that every time you launch a new microservice, you essentially get these features automatically, or with the least amount of set-up.
Example Project Template
Here is an example of a serverless project template to get you started - microservice-starter
Prerequisites
- Install Java 8, Groovy, Kotlin, and Gradle - I highly recommend using SDKMAN to install any JVM-related packages.
- Install NodeJS and the Serverless Framework
- Amazon Web Services, GitHub, Travis CI, CodeCov and Sentry accounts
Create a new Serverless project
Using the Serverless Framework, you can create a new project by providing the base template microservice-starter:
This project is pre-configured to use the following development tools and services:
- Groovy / Kotlin - Development Languages
- Gradle - Dependency Management and Build Tool
- Spock - Test/Specification Framework
- Serverless Framework - Serverless Management and Deployment Toolkit
- Travis CI - Continuous Integration and Continuous Deployment
- Jacoco / CodeCov - Code Coverage
- Sentry - Automatic Error and Bug Tracking
This project makes a few assumptions before you are able to deploy the service in AWS.
First, you need to setup your AWS credentials/profiles in ~/.aws/credentials file.
Now you can go to the project directory, build the binaries and deploy to the DEV environment.
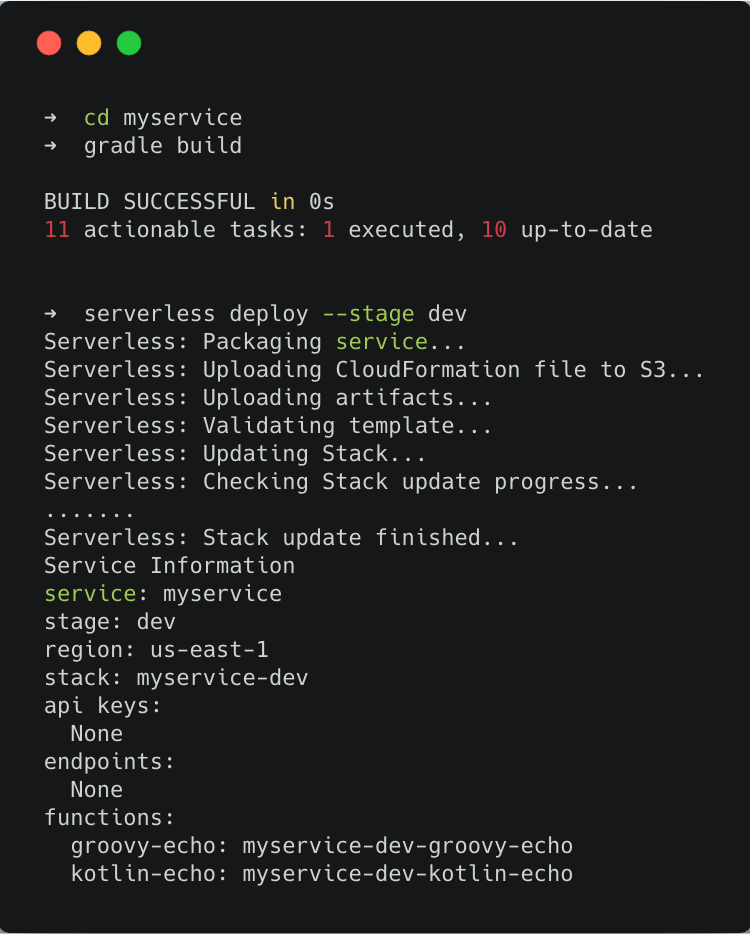
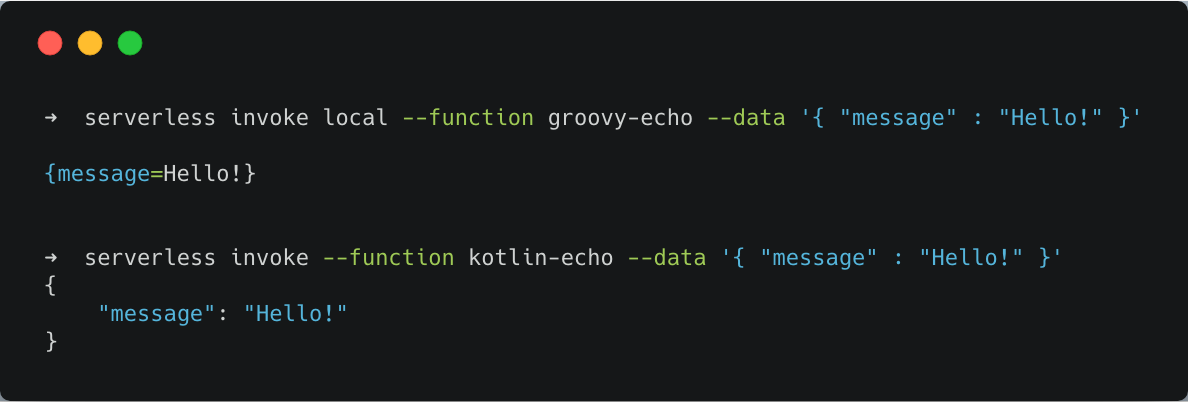
Test the functions locally or invoke the real instance in AWS to verify:
Additional Conventions / Configurations
Bug Tracking and Error Reporting:
- This project uses Log4J to automatically create trackable bug issues in Sentry whenever a message with the
ERRORseverity is logged vialog.error("..."). - Update the serverless.env.yml file to provide the
SENTRY_DSNenvironment variable so that issues are created in the appropriate project in Sentry.
Travis CI for Continuous Integration
- When the project is enabled in Travis CI, the provided
travis.ymlwill autodeploy the service to the dev AWS Environment. - The
DEV_AWS_KEYandDEV_AWS_SECRETenvironment variables must be provided in .travis.yml. - Code Coverage reports are automatically uploaded to CodeCov if the
CODECOV_TOKENenvironment variable is provided in .travis.yml.
VPC for Security and Access Restriction
- If deploying the microservice in a VPC, provide the necessary configuration - account ids, vpc ids, subnet ids and security group ids - in the serverless.yml file and uncomment the
vpcsection here.
Conclusion
As you can see, by using pre-configured template projects to initialize and create your services, you ensure that your new services have a solid foundation that utilizes consistent patterns and tools. Having this platform-wide consistency and standards accross all of your services significantly reduces the amount of time spent with management and configurations.
In a future blog post, I will go over the microservice-starter template project in more detail and show how to use Travis CI to create a single generic build job to deploy these Serverless-based microservices to the Production environment.

